What I did
- Skill : Python, CasADi ipopt
- Keywords : Stochastic MPC, Uncertainty Propagation, Feature Extraction, Sampling based approach
In the research, we want to extract features (i.e., compressed expressions) of uncertainty propagation over the constraints and the objective fucntion. If we use feedback policies, the uncertainty propagation is a function of feedback policy parameters (e.g. affine feedback gains, etc). To extract the feature parameters, we can use feature extraction techniques such as SVD based PCA, autoencoder and so on.
In this research, we conisder uncertain linear systems with affine disturbance feedback policies. Therefore, SVD can choose the feature policy parameters by ignoring some parameters which do not affect the constraints. Therefore, we can optimize the only feature policy parameters during online optimization so that it can improve computational speed very much.
It can extend to more complex parameterized feedback policy such as DNN. Deep RL basically relies on the DNN as the standard form of control/action policy. The principles of feature extraction of the policy parameters would be helpful to lightweight model development for control policy .
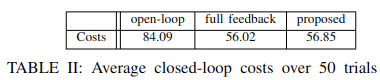
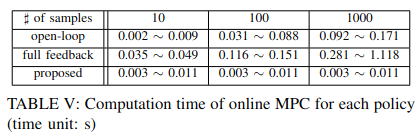
The proposed approach has similar control performance but much faster computation as described below.